
Like the princess she thinks she is, my two-year-old daughter regally commands me to prepare her favorite drink. “I want a cherry in and cherry out, please!” she informs me. For those uninitiated, this means that she would like her water mixed with a tiny bit of grenadine, and a maraschino cherry on the side, of course served in her special sippy cup.
Working with data inside your business is surprisingly like working with toddlers. I can get my daughter what she wants because we both have a shared understanding of what her label means. The actual words we use are irrelevant, but the fact that we use the same words is critical. And when communicating specific information between more than just a mom and her princess, you have much less leeway to simply make up new terms.
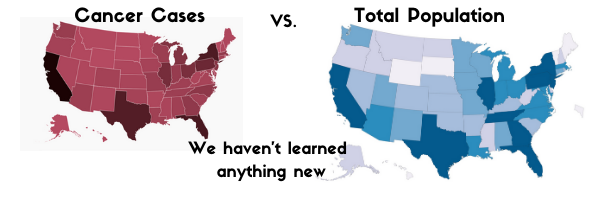
Once a boss of mine and I were trying to understand how charges for a certain procedure differed across our state’s hospitals. “Can you calculate the variance of the dataset?” he asked me. Easy. Variance in stats has a well defined formula, and in fact my analytic software allowed me to produce the number with a quick click. I brought him the number a moment later, but he frowned. “This doesn’t help me much,” he said. I was confused. I’d brought him exactly what he’d asked for. “How does this show me how many hospitals are high or low, and where the rest sit?” Still confused, I had to ask him to elaborate on exactly what he was hoping “variance” would tell him. As he spoke, I realized he had use the word variance not as I had interpreted it – a defined statistical calculation called “variance” – but as a lay person would use the English word “variance” to mean “how something varies.” Of course! Except it was not obvious at all.
This is just one reason why words matter in data. As much as we analysts may try otherwise, as humans we talk in words, not numbers. Non-experts must find the words to explain what they are looking for to analysts, and analysts must translate those words into analytic actions. And in reverse, analysts must then take those analytics and find the words to convey their meaning and insight to the end users. When we don’t have a shared vocabulary, or worse, when words can mean different things depending on the background of the listener, mistakes and confusion will be the inevitable result.
As I shared in an earlier post, one of the first ways we can avoid these confusions is to ask the deeper question of why. Why does the request want this specific number or analysis? What is the intended use of the analysis? These simple questions can surface misunderstandings before any misdirected work is wasted, and goes a long way to ensuring a useful result.
While many of the terms and words everyone needs to know are external words, like variance, there will also be internal words that you’ll have to make sure are defined consistently and understood evenly. For example, if your customer support teams asks to see how many people are churning off your subscription software project, what does churn actually mean? At first it seems obvious – it’s subscriptions that have ended. But that might not be how everyone sees it. For example, should it include start-ups using the software who went bankrupt or shut down? How about subscriptions for small companies that ended when the company was bought out and merged into the larger enterprise subscription? Words like “churn” seem to have a single, obvious definition but may vary widely when it comes to actually calculating or interpreting the numbers. To succeed with analytics you have to take the time to make sure everyone knows what they mean.
A bigger step is to take the time to ensure a basic level of data training for your whole organization. There are few roles that don’t touch some kind of data or analysis, but unless you are a specialist you likely haven’t had any formal data training. When bringing data training to a broad audience, it’s important to focus less on technical topics (no one needs to know how to calculate standard deviation!) and more on developing the vocabulary to understand results (what does “two standard deviations from the mean” actually tell us?). So much data literacy training, often now called data fluency, focuses on trying to turn everyone into data masters. But like learning any foreign language, fluency doesn’t have to be everyone’s goal. Some people might want to read War and Peace in its native Russian, but others of us may just want to be able to visit St. Petersburg and make our way around.
I’ve started calling this kind of familiarity training, “data conversancy” to distinguish it from more technical data literacy training. As end users, not creators, of data, we don’t need to be fluent. We just need to know how to follow directions from a local or ask where the bathroom is.
Now the question is, when your boss orders her version of “Cherry in, cherry out,” will you know what she means?
{kind=link}